Synthetic Personas: A Guide to Faster UX Research
Discover synthetic personas for faster, continuous UX research. A practical guide for designers, PMs, & researchers to optimize their work with Uxia.

It's not a lack of empathy that hinders understanding users. Instead, the problem stems from research arriving too late. By the time interviews are scheduled, prototypes are ready, stakeholders want answers, and the product team has already made half the decisions.
That's why synthetic personas have become such an important category in AI research. They give teams a way to model likely user perspectives earlier, test assumptions faster, and keep feedback flowing between major rounds of human research. Used well, they help researchers and product teams ask better questions sooner. Used badly, they produce polished nonsense.
I've seen that distinction up close while building research workflows around AI testing. The useful version isn't a magic user replacement. It's a structured simulation system grounded in evidence, constrained by context, and validated against real people. If you're already working with UX personas, usability studies, or concept testing, that's the mindset that matters.
Introduction What Are Synthetic Personas
A synthetic persona is an AI-generated representation of a target user segment. It isn't a random fictional profile and it isn't just a chatbot wearing a demographic label. The useful form is an archetype grounded in real behavioral evidence, customer knowledge, survey data, research artifacts, or other documented inputs.
Traditional personas usually live in slides, PDFs, or workshop boards. They describe a type of user. Synthetic personas go further. They make that segment interactive. Teams can use them to simulate reactions to concepts, explore likely friction in flows, and pressure-test assumptions before they invest in live studies.
That shift matters because product teams don't only need polished research outputs. They need a way to ask questions continuously. A fintech team may want to check how a cautious first-time investor interprets a risk disclosure. An ecommerce team may want early signal on whether a returns flow creates doubt. A healthcare product team may want to understand how an anxious caregiver reads appointment language. In each case, a static persona document helps a little. An interactive synthetic persona helps more.
The field became much more visible in the 2020s, and practical guidance published in 2026 describes synthetic personas as digital participants used for surveys, interviews, and product evaluations. That same guidance points to teams using them to compress research cycles from weeks to under 24 hours when the system is calibrated carefully, as described in PyMC Labs' guide to synthetic consumers.
If your team still treats personas as one-time deliverables, it helps to revisit how audience definitions are built in the first place. This guide on creating a user persona strategy is a useful companion before you move into synthetic testing.
Practical rule: Treat synthetic personas as working research instruments, not branding artifacts.
Demystifying AI Research Terminology
What exactly are teams testing when they say they used "synthetic personas"? In practice, three different objects get collapsed into one label, and that confusion leads to bad study design, inflated claims, and weak comparisons across tools.
Synthetic persona means the archetype
A synthetic persona is the model of a user segment. It defines who the simulated participant is supposed to represent.
In practice, that means more than age, role, or income band. A useful persona captures goals, constraints, expectations, domain knowledge, trust thresholds, and the context around the task. For a B2B SaaS product, that could be an operations manager at a mid-market company who needs fast reporting and gets frustrated by setup friction. For ecommerce, it could be a repeat mobile shopper who compares prices quickly and abandons checkout when fees appear late. For healthcare, it could be a patient managing a chronic condition who reads carefully but loses confidence when language becomes clinical or vague.
If the persona is shallow, every result built on top of it will be shallow too.
Synthetic user means the instantiated participant
A synthetic user is a specific simulated participant generated from that persona.
The distinction matters. "Small business owner comparing accounting tools" is a segment description. A synthetic user is a concrete participant with a scenario, preferences, prior experience, and likely behaviors. That participant can attempt a signup flow, react to pricing copy, explain confusion step by step, or compare two interface options.
At Uxia, the persona sets the audience definition. The synthetic user is the unit that performs the task and produces outputs researchers can inspect, such as reasoning traces, action paths, objections, and missed expectations.
A persona defines the pattern. A synthetic user is the participant generated from that pattern.
Synthetic panel means the group
A synthetic panel is a set of synthetic users run through the same study so a team can look for patterns instead of isolated reactions.
That is usually the level where the work becomes useful to product and research teams. One simulated participant can surface an interesting edge case. A panel shows whether the same hesitation, misunderstanding, or trust break appears often enough to justify design changes.
Examples are straightforward:
Fintech onboarding: a panel can show repeated hesitation around identity verification or risk disclosures.
Enterprise software navigation: a panel can surface recurring confusion around permissions, role switching, or dashboard hierarchy.
Ecommerce checkout: a panel can reveal whether trust drops at shipping costs, payment choices, or discount code entry.
Why the distinction matters
A lot of hype in this category comes from treating these terms as interchangeable. They are not interchangeable, because each one supports a different research job.
Term | What it is | What it's for |
|---|---|---|
Synthetic persona | Audience archetype | Framing who you want to learn from |
Synthetic user | Specific simulated participant | Running an actual task or interview |
Synthetic panel | Group of simulated participants | Finding patterns across responses |
This is also where teams make practical mistakes. If a vendor says it tested with "synthetic personas," ask whether that means one archetype description, one generated participant, or a full panel with repeated runs. Those are very different levels of evidence. A single generated user is useful for exploring hypotheses. A panel is what supports prioritization.
The category is getting more serious because benchmarks are starting to measure it against real human data rather than product demos. As noted earlier, PyMC Labs reported that, across 57 real consumer surveys with 9,300 participants, synthetic respondents reached 90% of human test-retest reliability and over 85% distributional similarity, while reducing research cycles to under 24 hours.
That does not make synthetic outputs universally reliable. It does show why precise language matters. Clear terminology helps teams choose the right method, set the right expectations, and avoid presenting simulated evidence as more definitive than it is.
When to Use Synthetic Personas and When Not To
Synthetic personas are most useful when the team needs directional insight before it commits to expensive decisions. They help with speed, coverage, and iteration. They don't remove the need for human evidence when stakes are high or context is emotionally complex.
Where they work well
The strongest use cases tend to be structured, early, and comparative.
Early concept validation: A B2B SaaS team can test whether a new dashboard concept feels useful or overloaded before moving into polished design.
Usability checks during sprints: A fintech team can run synthetic users through onboarding or card-freeze flows to spot trust and comprehension issues before recruiting live participants.
Audience simulation for edge contexts: An ecommerce brand can simulate first-time shoppers, international buyers, or low-confidence mobile users to find friction hidden by internal familiarity.
Scenario pressure testing: Enterprise teams can compare how admins, managers, and end users interpret the same workflow.
Study preparation: Researchers can use synthetic outputs to sharpen discussion guides, identify weak assumptions, and decide what to validate with humans.
Nielsen Norman Group puts the boundary clearly. Synthetic users are useful for desk research, generating hypotheses, and preparing studies, but not for final decision-making, as discussed in their article on synthetic users.
Where they are not enough
Synthetic personas become weaker when the question depends on lived experience that the model can only approximate.
They are not the right tool for:
Final go or no-go decisions
Market sizing or demand forecasting
Deep ethnographic work
Emotionally charged healthcare journeys
High-risk policy or regulated service design without human validation
That same Nielsen Norman Group guidance notes that these systems are strongest for structured tasks and can reach 85 to 90% parity with human testers there, but are weaker for emotionally complex research. That's a useful threshold. If the task is procedural, comparative, and interface-bound, synthetic testing can contribute meaningfully. If the task depends on grief, fear, identity, stigma, or social pressure, don't overclaim.
A practical decision filter
When deciding whether to use synthetic personas, I use a simple filter:
Is the question exploratory or decisive?
Exploratory is a good fit. Decisive needs human confirmation.Is the task structured or emotionally layered?
Structured tasks suit simulation better.Do we have grounded source material?
If the persona is based on weak assumptions, the output will sound confident and still mislead.Will a wrong answer create real product risk?
If yes, synthetic testing should support the study, not replace it.
If you'd be uncomfortable defending the finding in front of a customer, regulator, or senior stakeholder, validate it with humans.
That balance is the opportunity. Synthetic personas aren't useful because they eliminate research. They're useful because they let teams do more of it earlier.
How to Create and Test with Synthetic Personas in Uxia
Good synthetic testing starts before any model generates a response. The hard part isn't pressing run. It's deciding what kind of user you're trying to simulate, what evidence grounds that profile, and what task you want that user to complete.
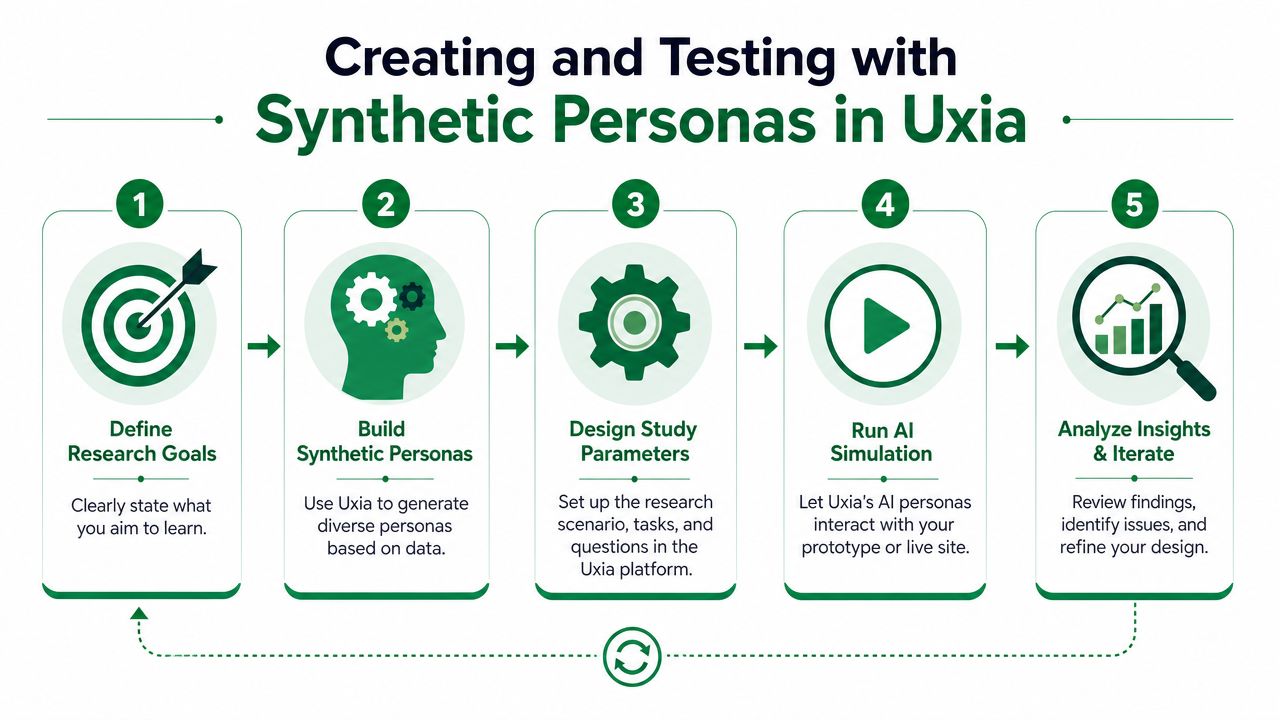
Start with evidence, not imagination
A rigorous workflow starts by anchoring the synthetic persona to real behavioral evidence. GWI emphasizes that personas built on real survey data are credible for enterprise decisions, while Stravito recommends attaching seed data, prompts, and model versions to each persona for validation, as outlined in GWI's guide to synthetic personas.
In practice, that means collecting inputs such as:
Existing research: Interview notes, usability findings, survey results, support transcripts
Behavioral evidence: Analytics patterns, funnel drop-offs, device preferences, usage context
Product knowledge: ICP definitions, market assumptions, help center themes, onboarding pain points
The mistake I see most often is starting with a stereotype. “Gen Z shopper.” “Busy founder.” “Non-technical admin.” Those labels are too thin. They don't produce useful test behavior.
Add situational context
One of the most revealing attributes we started using early wasn't age or country. It was context.
A user trying to complete a task calmly at home behaves differently from the same user trying to complete it while traveling, under time pressure, on an unfamiliar device, or in a second language. That detail changes what counts as friction.
For example, a local commuter may tolerate a payment redirect in a transport app. A first-time international visitor may read that same step as a trust problem. The persona becomes more credible when it includes what the user is trying to do, where they are, and what pressure they're under.
Configure the study properly
Once the persona is defined, the test setup should be explicit. In Uxia's AI user research workflow, that usually means defining testers, configuring the mission and scenario, running the study, and reviewing the report.
The parameters I'd always tune are:
Audience definition
Demographics matter, but they aren't enough. Include product familiarity, language, digital confidence, and domain knowledge.Mission and scenario
Give the synthetic user a concrete job. “Buy a one-time train ticket and request a receipt” is stronger than “explore the payment flow.”Prototype or live flow
The user needs something real to interact with. Static prompts alone won't surface navigation friction.Research questions
Focus on what you want to learn. Trust, comprehension, discoverability, decision confidence, or expectation mismatch.Variation across users
Generate multiple synthetic users from the same persona family so you can compare patterns instead of relying on one voice.
Review outputs like a researcher, not a spectator
A useful report should show more than a summary. It should capture actions, think-aloud reasoning, likely confusion points, and recommended fixes.
At this stage, I'd look for three things:
Repeated signals: Issues that appear across users deserve attention.
Expectation gaps: Moments where the interface behaves differently from what users think will happen.
Suspicious fluency: If every response sounds polished but shallow, the persona may be under-specified.
Rich inputs create useful synthetic users. Thin inputs create generic AI theater.
For B2B SaaS, that might mean testing admin setup, permissions, and reporting terminology. For fintech, it often means disclosure language, KYC trust moments, and transfer confirmation. For ecommerce, checkout confidence and returns clarity matter most. For healthcare and enterprise software, context and terminology usually drive the highest-risk misunderstandings.
A Real-World Example Uncovering Hidden UX Issues
The most instructive synthetic tests are rarely about giant design failures. They're about moments that look acceptable to insiders and still create doubt for the intended user.
A good example came from a public transport ticket-purchase flow in Amsterdam. The target user wasn't a generic traveler. It was a first-time international tourist trying to buy a one-hour transport ticket with a Mastercard and request a receipt.

The issue human testing missed
Human testers completed the task, but they didn't flag one of the most important trust problems in the journey. During payment, the app redirected users to an external Ingenico page that showed Dutch-language labels even though the main flow was in English.
That detail mattered because the task sat at a sensitive moment. The user was about to enter payment information on a different domain, in a different language, with little reassurance. For a local rider, that might feel normal. For a tourist, it can look unsafe or broken.
What the synthetic testers noticed
In the synthetic study, all 10 out of 10 AI testers raised concern about the external domain, the language switch, and the lack of reassurance before entering card data. They specifically identified Dutch labels such as “Verzenden” and “Kaartnummer” as barriers for non-Dutch-speaking visitors.
The important part wasn't just that the system found a usability issue. It found a trust issue in context.
That's the difference between a generic persona and a well-defined one. If the simulated user had been “adult traveler,” the output would have been flatter. Because the profile included first-time status, international context, payment intent, and language expectations, the synthetic testers interpreted the moment as the user would.
Context often explains more behavior than demographics do.
The fix was simple
The recommended changes were straightforward:
Keep language consistent: Preserve the selected interface language on the payment page
Explain the redirect: Add a short message before the handoff to the secure payment partner
Reduce trust friction: Translate key payment labels so users know what they're submitting
This kind of issue shows why synthetic personas matter in practical UX work. They don't just help teams simulate “who” the user is. They help teams simulate how that user reads a moment.
Measuring the ROI of AI-Powered User Testing
Teams don't adopt a new research method because the terminology is elegant. They adopt it because it changes delivery speed, insight quality, or study cost in a way stakeholders can see.
The clearest benchmark I've seen from Uxia came from the same Amsterdam testing workflow. It's useful because it compares a full synthetic study against a traditional panel on concrete operating metrics rather than vague efficiency claims.
What to measure
When teams evaluate synthetic testing, I'd focus on five KPIs:
Time to insight
Usability issues found
Depth of feedback
Usable completion rate
Cost per study
Those metrics capture whether the method helps research operations, not just whether the demo looked impressive.
Benchmark comparison
Metric | Uxia (10 Synthetic Testers) | Human Panel (5 Testers) |
|---|---|---|
Full testing cycle | 25 minutes | 748 minutes |
Usability issues found | 17 | 4 |
Relative issue coverage | 4.25x more issues overall | Baseline |
Average verbal feedback per session | around 2,200 words | roughly 300 words |
Relative feedback depth | 7x | Baseline |
Cost comparison | 65% cost savings | Baseline |
A few details matter here.
First, the study cycle completed in 25 minutes with Uxia compared with 748 minutes for traditional human testing. That made the synthetic workflow roughly 30x faster from setup to insight.
Second, the synthetic testers surfaced 17 usability issues versus 4 from the human testers. Every issue found by the human panel had already been independently identified by the synthetic study, and no unique insights came exclusively from the human panel.
Third, the AI testers produced around 2,200 words per session, compared with roughly 300 words from human testers. That difference matters because many teams don't just need a pass or fail result. They need reasoning they can inspect.
If you're trying to build a business case for earlier validation, this broader argument about making product choices traceable is close to the same logic behind data-driven design.
How to read these numbers correctly
These figures don't mean synthetic testing replaces all human work. They show that for the right class of UX questions, teams can reduce turnaround time sharply, widen issue coverage, and lower study cost without waiting for panel logistics.
That makes synthetic testing especially useful in sprint-based environments, concept screening, pre-launch QA, and design iteration cycles where speed changes the quality of decision-making.
The Future of Research is Continuous and AI-Augmented
What changes when research can run every week, or every day, instead of only at major milestones?
The answer is not just speed. It is a different operating model. Teams can move from occasional studies to an always-on research loop where assumptions are tested earlier, design choices are checked more often, and evidence stays closer to the work happening in product, design, and growth.
That shift changes the role of synthetic personas. They are not a replacement for users, and they are not the same thing as a panel. They are a testing instrument. Used well, they let teams simulate likely reactions from defined audience profiles between rounds of live research, which is very different from claiming they represent ground truth.
Research judgment becomes more demanding in that model. Teams still have to decide how a persona is grounded, which questions are safe to test synthetically, and where only human participants can answer with confidence. They also need governance. Synthetic personas can reflect gaps and bias in the materials used to create them, especially when the source data leaves out people who are already underrepresented, as discussed in Bluetext's analysis of synthetic personas.
Mature teams tend to handle this in a few consistent ways:
They separate terms clearly: a persona is a modeled profile, a user is a real person, and a panel is a recruited group of humans.
They validate high-stakes findings with humans: synthetic testing helps prioritize what to investigate, not declare a final answer.
They track provenance: seed data, prompts, model settings, and revisions stay attached to the output.
They check for missing populations: before trusting results, they ask who was not represented in the source material.
They build it into the workflow: synthetic testing is part of iteration, QA, and concept review, not a novelty project run on the side.
The long-term ROI surfaces. Continuous, AI-augmented research reduces the dead time between question and feedback. It also gives researchers more chances to spend live sessions on the hard questions: motivation, trust, emotion, edge cases, and behavior that only appears in real contexts.
Uxia fits into that workflow in a practical way. Teams can define audience-specific AI testers, run step-by-step UX tests on prototypes or live flows, and review reports that capture behavior, think-aloud reasoning, and usability issues earlier in the design cycle.
The future of research is not automated certainty. It is a tighter system for deciding what to test with synthetic personas, what to confirm with real users, and how to keep learning continuous instead of episodic.